SIMD-pathtracer
Project Checkpoint: SIMD Parallelization of a Path Tracer
Authors: Michelle Ma, Rain Du
Progress Summary
We have roughly adhered to our schedule, made some considerable progress, and made plans for the remainder of this project.
Instead of using C++ math libraries or call C++ functions associated with complex classes and inheritance from ISPC, we basically ported the whole path tracer and everything it uses to ISPC. Initially we disabled many quality-of-life features for the sake of simplicity (materials, direct lighting, depth of field). The initial image rendered are a more noisy version(as shown in figure 1), but reflects the essential features of ray tracing (showing ray reflections and lights changing based on different colors of the background). Once we made our initial progress we started adding them back.

Figure 1: Image Rendered by an Initial Noisy Version of Our Parallel Ray Tracer
As described in the proposal, we managed to get rid of recursion in the ray tracing routine. Instead of tracing a certain ray till it finishes (returns to the light source), we replaced it with a new trace_ray function that takes a RayTask struct as input, traces the input ray for one bounce, stores its partial output, and either mark the input RayTask struct as finished, or update it to become a new task that contains information about the next bounce, so that it’s ready to be picked up by any ISPC instance and executed again. In other words, now our trace_ray function takes in one ray tracing job. Since we only trace the rays for one bounce, the instruction streams for each ray are identical, creating space for further vector utilization improvement. This implementation change made SIMD parallelization much more convenient, and we will describe the details of our optimizations below.
Apart from simply using parallel statements in ispc like foreach to implicitly vectorize the computations in for loops, we used ispc tasks to map tasks of tracing a batch of rays to different cores. In our implementation, each task contains rays sampled at a batch (1024 / num_threads) of pixels. To limit the amount of memory allocated, we use shared space model, allocating a single array of memory enough to store rays in a single batch, and wait for all tasks to finish rendering within a batch before processing to the next.
As described in lecture, since the depth of tracing rays in a batch can differ greatly, the vector utilization might not be good enough if we simply trace every ray in the batch until they finish. Therefore, with the code restructuring explained above, we changed the code to tracing rays in the batch for one bounce. At the end of each trace, we conduct a parallel scan with peaks finding to gather unfinished rays together, then we continue the vectorization in the next iteration on the gathered rays array. This improves vector utilization since the batch size is way larger than the vector width, and essentially we’ve reduced total number of vector lanes used, further improving the runtime.
We also identified more places that can be optimized: the memory locality and cache misses still remain an issue. Since the batch size can be significantly greater than the cache line size, tracing rays in the same batch for two consecutive iterations can result in unnecessary memory misses. We can definitely change our loop structure to heuristically trace the same rays for a certain iterations before processing to the next mini batch (rays that fit in a vector). There can be some tradeoffs between vector lane utilization and memory localities. In addition, since we added the material differentiation functionality back, many rays might be bouncing on to the same material. Therefore, we can explore potential material data reuse and group rays potentially reflected on the same material together to further improve locality. This can be implemented as sorting based on locations and angles, or using extra storage to rearrange memory accesses to the material information. Moreover, since we are currently using parallel scan in place, there can be unnecessary ray structures copying. We plan to further optimize this by scanning indices and access rays from the same array rather than copying a new array each time. If time permits, we will port our project to cuda code to compare and potentially observe further speedups.
Preliminary Results
We compared our results with the sequential implementation in C++. Although the ISPC version is essentially a separate implementation that uses its own math functions, random number generators, etc., making the runtime potentially a little unfair to compare with, the promising speedups made us confident on further optimizations. Below are the detailed runtimes and speedups we measured.

Figure 2: Cornell Box Image Rendered By Our Parallel Ray Tracer (with full functionalities)
| C++ | ISPC vw=4 | ISPC vw=8 | ISPC vw=16 | |
|---|---|---|---|---|
| 1 thread | 194s | 134s | 90s | 71s |
| 2 threads | - | 83s | 48s | 41s |
| 4 threads | - | 50s | 32s | 29s |
| 8 threads | - | 47s | 31s | 30s |
| 16 threads | - | 45s | 27s | 25s |
We rendered the image in figure 2 (a mirror prism in the cornell box, width = 800px, height = 600px, 100 camera rays/pixel, maximum 8 bounces) using our sequential C++ implementation and parallel ISPC implementations. The detailed runtimes are reported in table 1, and the related speedups of parallel programs with respect to the sequential version is shown in figure 3. The results are generated on the machine with the following specs:
Macbook Pro 13”
CPU: 2.4 GHz Intel Core i5
Memory: 8 GB 2133 MHz LPDDR3
Graphics: Intel Iris Plus Graphics 655 1536 MB
Since the machine has only 4 cores, we also observed limited improvement for parallel ray tracers with number of threads beyond 4. The slight improvement might come from more threads enabling latency hiding from context switches. In addition, the programs did not achieve close to linear speedup because of the computation overhead such as gathering unfinished rays via scan.
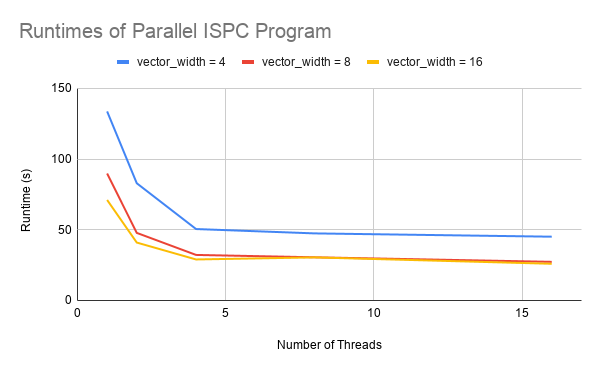
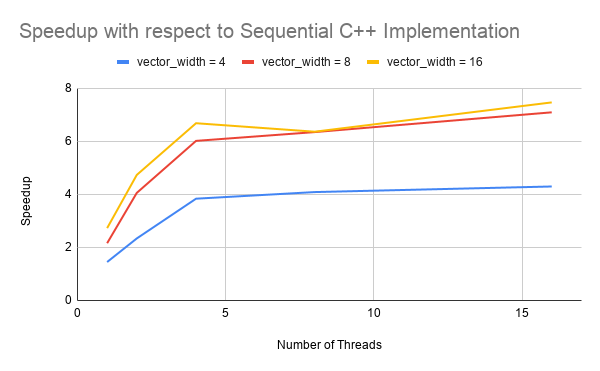
Figure 3: Runtimes and Speedups of Parallel ISPC Ray Tracer
Planned Deliverables
Our planned deliverables are roughly the same as the ones we visioned in our proposal:
- Images rendered with the sequential path tracer, single-threaded ISPC patht racers of different vector widths, multi-threaded ISPC path tracers of different vector widths, and possibly a CUDA path tracer, and each image’s rendering run time.
- Speedup graphs of the above path tracers
- A downloadable build of our path tracers, as well as a link to the source code with build instructions. The build will read FBX and configuration files, render to a .ppm image, and output its render time.
- A poster with more information related to our project with sections including introduction, summary of our effort, results, explanations of results and the analysis on all expected as well as any less-than-ideal behavior.
- With our current speedups, we could present a live demo using an interactive session, but with significant delays. However, if we see promising speedups in our subsequent optimizations, an interactive live demo can be more engaging to the audience and can present the results more intuitively.
Issues and Concerns
For now, the major concern would be whether we can successfully reduce the memory locality issues. As described above, there are some data reuse that we can find when rendering similar rays. However, if we would dynamically group rays on similar materials, the computational overhead can be significant due to potentially unnecessary regrouping, data transferring, as well as incorrect grouping (since it’s only heuristic based). We are not really sure whether this path would worth exploring in terms of improving data reuse and memory locality.
Other than this issue, we do not foresee any further problems with our project.
Revised Schedule
If we divide our remaining two weeks of time into 4 periods (with one period being half a week), we would plan each period as follows:
Period 1
- Implement and experiment with grouping of rays based on what material they hit [Rain]
- Further optimize rays gathering by removing unnecessary rays copying. Restructure the ray tracing loops and render each ray for multiple bounces per gathering to reduce cache misses and improve data reuse rate. [Michelle]
Period 2
- Potentially rearrange material information accesses to improve locality.[Michelle]
- If the regrouping of rays optimization went well, start porting our code to CUDA and make sure the sequential version code compiles successfully [Rain].
Period 3
- Converting ispc tasks to mapping of tasks to cuda threads. [Michelle]
- Add any additional optimizations (rays gathering and regrouping) to the cuda ray tracer.
Period 4
- Clean up cuda version of ray tracer. Measure and document speedups[Michelle]
- Prepare and clean up code for our deliverable(s) [Michelle], poster [Rain], website [Rain], and final project writeup [Michelle \& Rain].
We expect the biggest challenge for the remaining work to be the idea of regrouping rays for better data reuse, and we. Therefore, we treat the cuda version of ray tracer as our stretch goals. We still expect us to closely follow the schedule as described.